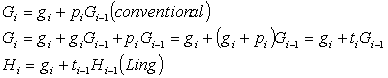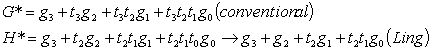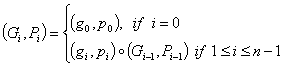|
|
||
07/02/04 |
|
|
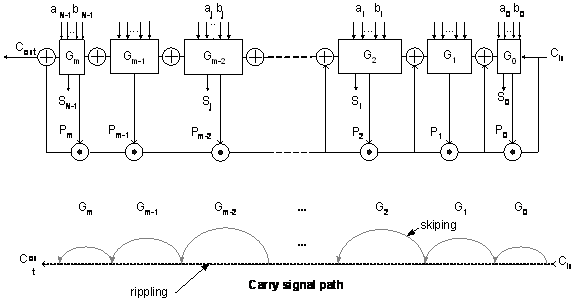
1. Ripple Carry AdderThe ripple carry adder is composed of a chain of full adders with length n, where n is the length of the input operands. 1.1 Full AdderThe following Boolean expressions describe the full adder.
where a and b are the input operands and p and g are the propagate and generate signals respectively. Carry is propagated if p is high or is generated if g is high. Thus, the sum S and carryout Co signals can be expressed as:
where Ci is the carry-in signal. 2. Carry Look-ahead AdderWeinberger and Smith proposed this scheme in 1958 [1]. It uses look-ahead technique rather than carry-rippling technique to speed-up the carry propagation. By using additional logics, group generate and propagate signals can be generated. Equation 3‑3, Equation 3‑4 and Equation 3‑5 show the logical expression of prefix-4 group generate, propagate and carry-out signals respectively. Thus, multiple levels of carry-lookahead logics can be used to propagate carry-in from the least significant bit (LSB) to the most significant bit (MSB).
3. Ling AdderAdder proposed by Ling is an improved version of conventional carry-lookahead adder [6]. This approach is faster and less expensive. It replaces the conventional propagate operator from a XOR with an OR gate which results in a much cheaper operation.
Rather than propagating the carry Gi as conventional carry-lookahead technique do, Ling’s approach replaces Gi by Hi, where
Hi is high means either there is a carry-in or a carry-out at ith bit. The generate operation can be reformulated as:
The group generate signal can also be reformulated as:
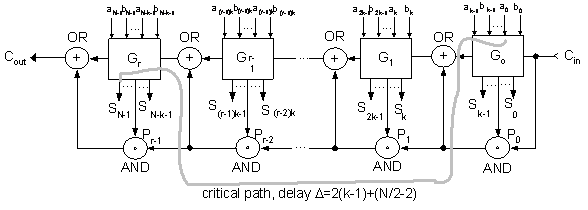
Equation 3-9 again shows Ling’s scheme would result in much cheaper carry propagation at the cost of more complex sum generation stage. 4. Carry-Skip and Variable Block AdderAlternative from carry look-ahead schemes, carry-skip scheme is proposed first by Kilburn et al to accelerate the carry propagation [2]. It adds additional group carry bypass paths to its ripple path and the carries can bypass the ripple path when the group propagate signal is high. Figure 3‑1 shows the basic structure of an N-bits carry-skip adder with k-bits per group [25]. The critical signal is generated at LSB, ripples through remaining k-1 bits in the least significant group, bypasses N/k - 2 groups, ripples through the k-1 bits in the most significant group and disseminates at the MSB.
Figure Basic Structure of Carry-Skip Adder [25] This scheme is faster than Ripple Carry adder with a small overhead in adding bypass circuitries to accelerate the carry propagation delay. However, the delay is linearly dependent on the number of bits, N. Oklobdzija and Barnes proposed a variable skip group scheme to optimize the delay of critical carry signal [8], [11]. Figure 3‑2 shows the general structure of this scheme. The least significant and most significant blocks are smaller and the intermediate blocks are bigger. This shortens rippling stages of the critical path. The total delay is shorter than that of carry-skip adder and it is no longer linearly dependent on number of bits, N.
Figure 2 Structure of Variable Block Adder [11] 5. Conditional Sum and Carry-Select AdderSklansky proposed the conditional sum addition in 1960 [3]. Rather than waiting for propagated carry signal to generate each sum, this scheme first generates sum and carry-out pairs by using both possibilities of carry-in signal at each bit position. The correct output is then selected upon the arrival of carry-in signal. The hardware complexity of this scheme grows quickly from its LSB to its MSB. Thus, in most designs, conditional sum addition is only implemented in part of the adder. Like carry skip schemes, carry select scheme divides adder into blocks of ripple carry adder with each with two replicas, one replica evaluates with carry-in of 0, the other one with carry-in of 1. This scheme is proposed by Bedrij in 1962 [4]. In this scheme, the carry-out from less significant block selects the sum and carryout of more significant block. Thus, the critical signal is generated at the least significant bit, ripples through the least significant block and then conditionally selects the output of succeeding blocks. The conditional sum addition described above is a special case of this scheme. 6. Prefix-Tree addersExtends from the idea of carry look-ahead computation, a class of parallel carry look-ahead schemes are formed targeting at high-performance applications [5], [7], [9]. These schemes rely on recursive carry computation as follows:
Thus,
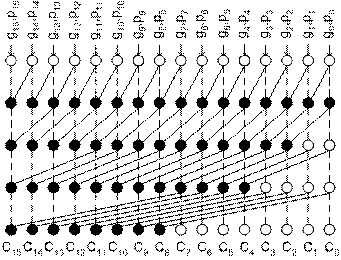
Thus, they are also called recurrence solver adders. There are two properties of this recursive formulation: · Ci = Gi for all i · The operator “o” is associative From this, different parallel schemes are formed. Figure 3‑3 shows a 16-bit prefix-2 tree structure using the recursive carry property described above. The addition can be complete in time O (log n).
Figure 3 16-bit Prefix-2 Tree Structure 6.1 Kogge-Stone AdderKogge and Stone proposed a general recurrence scheme for parallel computation in 1973 [5]. The tree structure of this generalization is shown in Figure 3‑3. Adders implemented using this technique is in favor due to the following: · Regular layout · Controlled fan-out However, they are nothing but prefixed carry-lookhead adders. The intermediate carries is generated by replicating the prefix tree shown in Figure 3‑3 at every bit position. Figure 3‑4 shows the resultant prefix graph of a 16-bit prefix-2 Kogge Stone adder.
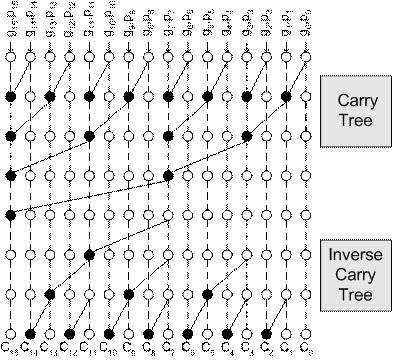
Figure 4 Prefix graph of 16-bit prefix-2 Kogge Stone adder 6.2 Brent-Kung AdderThe replicated Kogge Stone structure to generate intermediate carries shown in Figure 3‑4 is very attractive to high-performance applications. However, it comes at the cost of area and power. A simpler tree structure could be formed if only the carry at every power of two positions is computed as proposed by Brent and Kung [7]. Figure 3‑5 shows a 16-bit prefix tree of their idea. An inverse carry tree is added to compute intermediate carries. Its wire complexity is much less than that of Kogge Stone adder.
Figure 5 16-bit Brent-Kung Scheme 6.3 Han-Carlson AdderLike Brent and Kung’s scheme, Han and Carlson also proposed a scheme to reduce the complexity of prefix tree [9]. Different from Kogge-Stone scheme, this scheme performs carry-merge operations on even bits only. Generate and propagate signals of odd bits are transmitted down the prefix tree. They recombine with even bits carry signals at the end to produce the true carry bits. Thus, the reduced complexity is at the cost of adding an additional stage to its carry-merge path. |
Copyright Advanced Computer Systems Engineering Laboratory, 2004
This site was last updated 07/01/04